GSoC Week 1 Recap
The first week of Google Summer of Code has ended, and so it's time for a recap post!
The main topic this week was PartDesign Mirrored, a fairly self-explanatory feature, with a show-stopping bug explained in FreeCAD issue 3006.
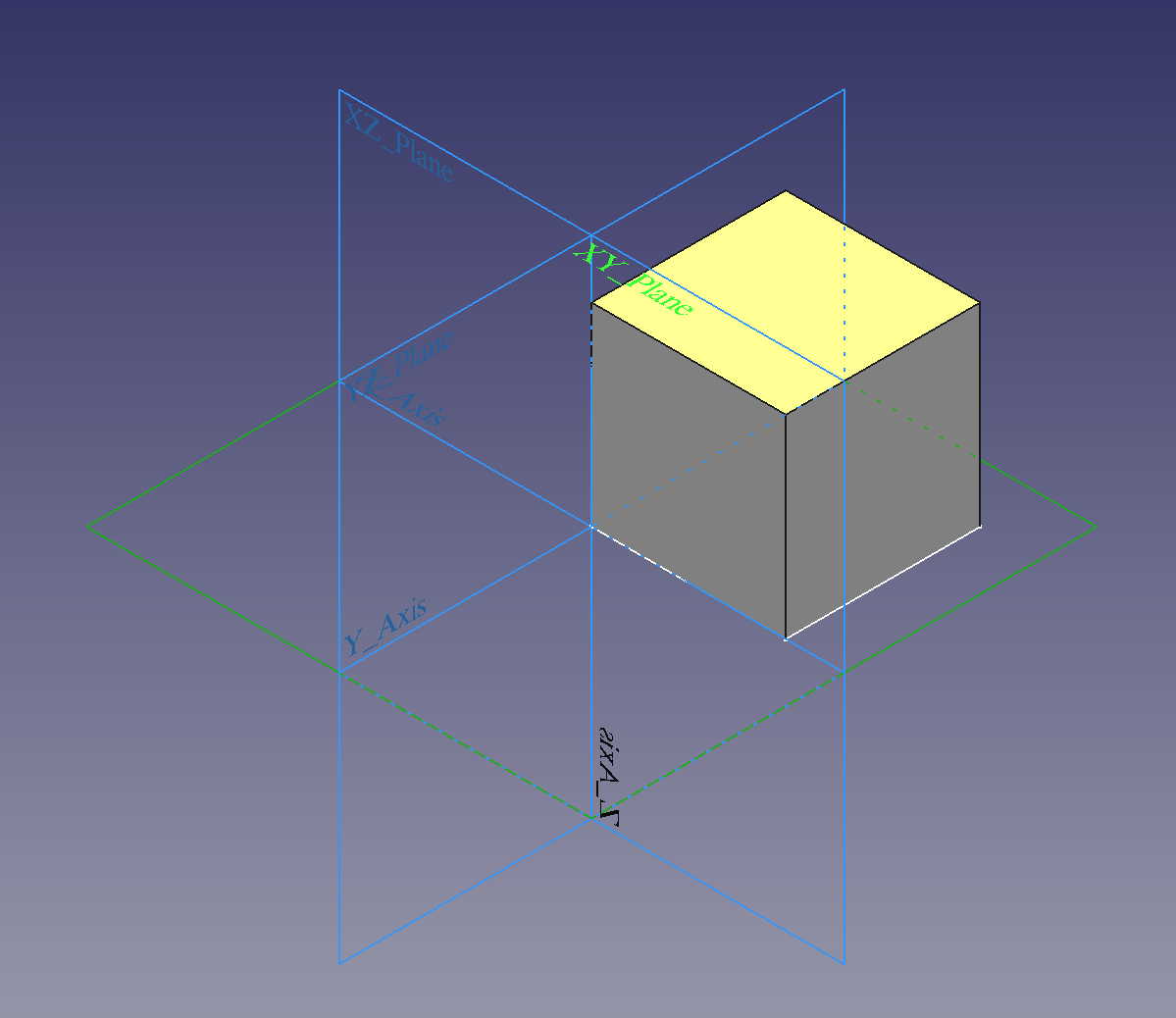
Figure 1. The base of my PartDesign Mirrored experiments.
In this picture, we have a simple 1 mm square sketch (pictured in white) attached to the \(xy\)-plane.
One corner is at the origin, and the sketch is the base for a Pad feature 1 mm high.
Length is handled internally as mm by FreeCAD, so this "unit cube" serves as a useful basis for testing behavior.
A useful alteration involves displacing this cube, say, 1 mm up the \(y\)-axis.
This constructs a case where mirroring not all mirrorings should succeed, but we'll get into that later.
Let's turn now to the bug itself, depicted in figure 2. The unit cube is supposed to be mirrored about its vertical sketch axis (the \(y\)-axis, pictured running off to the top right.) Obviously, it's not, and the failure is helpfully represented in red.

Figure 2. FreeCAD bug 3006 in action.
Note that the body diagonal of the mirrored part should run from the origin to \((-1, 1, 1)\). Instead, it's going to \((1, -1, -1)\), in the opposite direction.
Well, this was my first really serious bug to tackle for the summer. I chose this as a way to really dive in, since it directly involves Open CASCADE, the open source C++ geometry kernel at the heart of FreeCAD.
However, my programming background is chiefly with Python (as well as JavaScript and Lua), all interpreted languages.
One nicety of that sort of language is that it can be very quick to debug and examine behavior using the interpreter.
There is a Python debugger, pdb, but I rarely needed to use it for my mostly personal-sized projects.
Even then, it's quite straightforward to use since you're already in an interpreter-native environment.
C++ is a very different beast. In this case, stepping through the code with a debugger was my only choice. I use Neovim as my IDE, though, so I wanted a way to combine the power of my text editor with my debugger. So, I found and set up LLDB.nvim, an LLDB frontend, with an event-based, non-blocking UI, session-saving, and "... takes advantage of Neovim's job API to spawn a separate process and communicates with the Neovim process using RPC calls."
Pretty nice. Anyway, I was able to step through the code and see exactly what was flying around, just like I wanted.
Figure 3. Neovim in an LLDB debug session.
So, what was the problem? Hah! Not so simple. Turns out there are at least four bugs here!!
First, the algorithm which first checks if the mirrored shapes are adjacent and thus, can be fused, was broken.
Once this failed, FreeCAD then attempts to generate a mesh from the shape, and then converts a generalized transformation object representing the mirroring into a matrix to put the mesh in the correct place.
It turns out that in Open CASCADE 7.0.0, the gp_Trsf API was changed so that gp_Trsf::VectorialPart() returns a 3x3 matrix including the scale factor.
The previous behavior was to return the homogeneous part of the transformation which does not include the scale factor, and the FreeCAD algorithm for constructing the 4x4 matrix for the mesh included multiplying every term by a scale factor.
In other words, the scale factor multiplication was happening twice. The scale factor I had observed in the debugger was -1, so this perfectly explained the inverted positioning of the failure result!
The third bug, of a much more minor nature, involved a a classic "failure... success!" message displayed in the event of a mirroring failure, and was easier to fix.
The fourth, though, was a bit trickier! It only appeared when fixing the mesh placement.

Figure 4. A strange, new mirroring bug.
This one was diagnosed by ickby, my mentor for this project. It turns out the failure meshes' faces were getting constructed inside out, and so the material's color was not considered "illuminated".
The three of us considered a few different options to get around this. One way would be to use Coin3D, FreeCAD's scene graph library, and change the material properties to define something that looked the same, illuminated or not. Another is to essentially duplicate each face with the second instance having an inverted normal, so that you're guaranteed to have an outward-facing face.
The fix ended up being much simpler than that! It was possible to simply change the vertex ordering. Originally, it was set to COUNTERCLOCKWISE.
However, in figure 4, you can see that simply changing it to CLOCKWISE would not be an obvious fix.
Abdullah also fixed this one, presumably by checking the docs for that option and finding that there was an "option C", UNKNOWN. That did the trick!
So now, PartDesign Mirrored is fixed and ready. Not a bad start for the summer!